*Sed ut perspiciatis unde omnis iste natus error sit voluptatem accusantium
Introduction
“Computer Vision”, a field of Artificial Intelligence that helps Machines to visualize this beautiful world. Computer vision has led to wonders in enhancing Artificial Intelligence. From pattern recognition to Human Pose estimation, And from Robot navigation to solid-state physics, computer vision has much more useful and helpful applications. Using computer vision and deep learning, we successfully give machines the ability to visualize and understand images, videos, etc. But revolution is fastened.
Earlier The Convolutions have given superlative contributions to computer vision and deep learning for medical research, business, technology, and many more. At the last technology can’t be stable it has to be refurbished.
CNN was first introduced in the 1980s by Yann LeCun. The sum of the product of pixels values and their weights is the actual mechanism behind convolution. CNN Mainly focuses on extracting features from the image such as corners, edges, color gradients, and much more. It typically comprises 3 layers that are convolution, pooling, and fully connected layers. In 2015 Microsoft’s research fabricated a highly deep CNN network that outperformed AlexNet, the network was about 200 layers deep. AlexNet was considered the most influential paper published ever in computer vision.
let’s recap the NLP.
In the case of Natural Language Processing(NLP), As we know it’s the sub-branch of Artificial Intelligence that helps the human being and computer to interact with each other, technically it is the technique to accord computers the ability to understand the human language and derive its essence. NLP is also a toolkit to handle text data with ease. Some popular natural language processing applications include sentiment analysis, text classification, speech-to-text, neural machine translation, etc.
But where exactly the CNN lacks?
2017 was the year when Google Brain, Google research, and the University of Toronto introduced the transformers, it abruptly took the NLP to the next level, it brought a transmutation into the seq to seq model. sequence to sequence models (LSTM/GRU i.e the RNN’s) was used to transform sequence from one form to another, but they too suffer from some adverse problems like vanishing gradient and the model used to handle sequence word by word i.e it took much time and was an obstacle for parallelization. Attention plays a very crucial role in the transformers architecture to extract salient features from the input data. we won’t go much deeper into transformers. I won’t go much deeper into the transformers, hopefully, You must be aware of the transformers architecture which made you read the visual transformer.
Various models were built upon the transformers architecture like the BERT, GPT, TransformerXL, XLNET and there are many more which bestow state-of-art performance.
Recently Google’s BERT has just brought a slight change into its Encoder architecture, which made BERT faster and accurate than before. If you wanna read more on this here is it below.
You might be wondering when the vision transformer will come into play, to understand the vision transformer you need to understand the Indept transformer working. Vision transformer is also a slight change to the transformer.
Vision transformer working and architecture [source]
As shown in the above diagram the images in the dataset are split into n number of patches of the same size s. i.e
The 2D image of size H *W is split into N patches where N=H*W/P² in sequence and Each patch is flattened into a 1D patch embedding by concatenating all the pixel channels in a patch.
they are further passed from the linear projection to get the desired input dimension.
Vectors are then position embedded as well as extra learnable embeddings are added to it, as we saw in the BERT the way we add classification tokens.
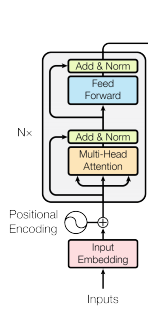
finally, the sequence of patch embedding vectors is fed to the transformers encoder, where the working is the same as in the native transformers encoder.
The inputs are normalized and passed through the multiheaded attention for learning local and global dependencies from the image, adding the residual from the input we pass it to the multi-layer perceptions from the normalization layer, and again the residuals are added.
Code Implementation of a vision transformer
We’ll try to implement the vision transformer model using PyTorch in Python
Import lib’s
import torch
from torch._C import dtype
import torch.nn as nn
from torch.nn.modules.conv import Conv2d
import torch.nn.functional as F
define the device object to use
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
empty cache
torch.cuda.empty_cache()
define parameters for image size, patch size, embedding dimension size, multilayer perceptron dimensions, number of layers, number of heads attention dropout rate, number of classes.
the further process involves embedding the patches, you might be wondering why I had used the convolutional for embedding patches. Lol, My title is refuting convolution. Convolution extracts feature more appropriately with suitable inductive baises, which leads to a rise in performance. The CNN is used to extract the low-level features in an image, and ViT is used for relating high-level concepts.ResNet or EfficientNet can also be trimmed to certain layers for extracting the features. patch embedding also can be done through a linear layer. which is commonly used by many. Further, we add the class tokens in the sequence of patches and passed with their positional embeddings through dropout regulation. Adding positional embedding helps the model to understand the structure of the image as well as its patch location.
The rest flow goes the same as for the native transformer Encoder.
The transformer Encoder part. This encoder layer can be stacked n times to extract some new information every time from each layer this results in good predictive power to the transformer
The Transformers Encoder consists of a multi-head self-attention and multi-layer perceptron. Where multi-head attention plays a crucial act by paying attention to the input sequence. Rather than only computing the attention once, the multi-head mechanism runs through the scaled dot-product attention multiple times in parallel.
An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key
A simple neural network is used to conclude a binary result. A perceptron is a linear classifier, that classifies input by separating two categories. The Multilayer perceptron consists of the linear functions, GELU activation (Gaussian Error Linear Unit), and dropouts.
class Mlp(nn.Module):
def __init__(self, emb_dim, mlp_dim, dropout_rate=0.):
super(Mlp, self).__init__()
self.fc1 = nn.Linear(emb_dim, mlp_dim)
self.fc2 = nn.Linear(mlp_dim, emb_dim)
self.act = nn.GELU()
self.dropout= nn.Dropout(dropout_rate)
def forward(self, x):
out = self.fc1(x)
out = self.act(out)
out = self.dropout(out)
out = self.fc2(out)
out = self.dropout(out)
return out
I have performed a classification task using ViT please star the repository if you find it helpful, or create a new issue if you found any.
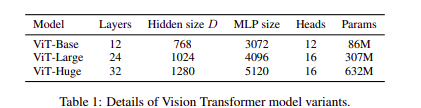
Variants
The paper has released 3 variant of the vision transformers which are adopted from BERT, the base one, which has 12 layers the large one which has 24 layers and the huge one which has 32 layers with 632M parameters. The smaller the input patch size yields larger computational model, as the formula for the number of patches exhibits
The vision transformer takes a bit longer time due to its low understanding of image data and hence requires a much higher quantity. The model is pre-trained from a large dataset and is finetuned with smaller data. Vision-Transformer has higher accuracy on a sustainably large dataset with reduced training time.
During fine-tuning, the patch size should be the same if compared to the patch size on which the model is pre-trained. Fine-tuning the model with Images of Higher resolution can give better performance.
As the Google blog displays, vision transformers performed poorly when pre-trained with fewer amounts of data, and it outperformed SOTA with sufficient i.e large enough training data.
Conclusion
Vit demonstrates excellent performance when trained on sufficient data, outperforming a comparable state-of-the-art CNN with four times fewer computational resources. — Google blog
Vision transformer pretends and is authentic in remitting better performance, that beats the state of art convolution neural networks. Self-attention again is the foremost component in ViT which pays attention to the predominant features of the image. Vit’s can be used as the replacement of convolutional pipelines. Vit is the measure to approach the scalable architecture in computer vision. It was a needful invention in the field of computer vision along with the increase in data and computing power.
https://github.com/AmitNikhade/Vision-Transformer