*Sed ut perspiciatis unde omnis iste natus error sit voluptatem accusantium
A sudden change to the encoder!
June 24, 2021

Transformers have gained tremendous popularity since their creation due to their significant staging. They have ruled the NLP as well as the Computer vision. Transformers-based models have been the all-time dearest.
Overview
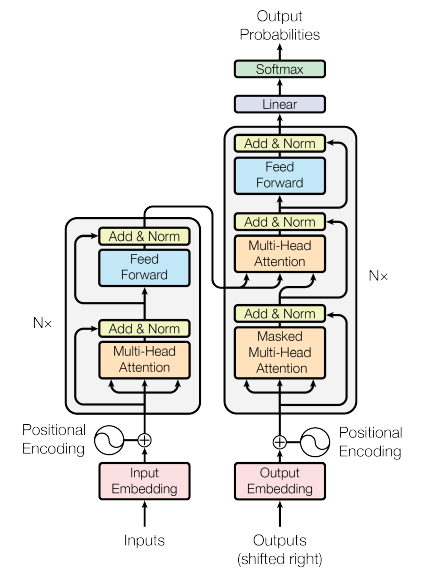
“Attention is all you need”. The paper describes the Transformer architecture where the encoder and decoder are stacked up. Both the architecture comprises normalization, feed-forward, and attention layers. The biggest advantage of transformers is their parallelizable nature. The Attention has played a crucial role in the transformers mechanism, which is responsible for its overall optimization
Parallelization replaces the seq2seq mechanism, which is feasible due to the positional encoding and the attention resulting in faster training as compared to earlier sequence to sequence models.

{kind=link}
Encoder
The encoder is composed of stacked identical n layers, where each sublayer of the encoder consists of multi-head attention and a feed-forward network with some normalization. The vectors passed as an input to the encoder are word as well as positional embedded.
Decoder
The decoder is a bit similar to an encoder with a little modification like double attention layers from which the second attention layer accepts input from the encoder and the previous decoder attention layer which is further passed through the feed-forward network.
Here comes the Attention
Firstly, attention was brought to the picture due to its attentiveness towards certain factors while processing the data. To state it in a simple manner, attention learns the context vector in such a way that it extracts and maps the important and relevant information from the input sequence using cosine similarity, and assigns higher weights to it, which leads to much accurate prediction. Its solves the vanishing gradient problem in the encoder-decoder mechanism.
In the transformer’s encoder part, the self-attention is used to pay attention to the input sequence in order to extract salient data from it.
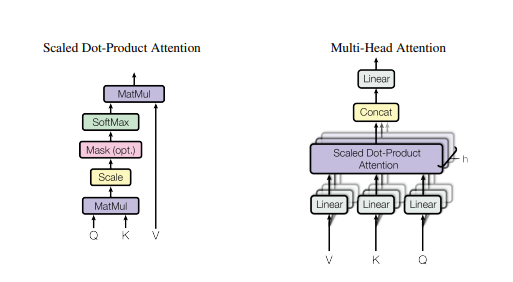
The Beast with many Heads
{kind=link}
The input fed to the Attention is in the form of three parameters, known as the Query, Key, and Value i.e (Q, K, V). All three values are the same vectors. In the encoder self-attention. The attention layer loops through its computations parallelly, multiple times. each of these computations is called an attention head. All of these attention calculations are combined together to produce a final score. there are three attentions used in the transformers architecture. The encoder self-attention handles the input sequence of the encoder and pays attention to itself, the decoder self-attention pays attention to the target sequence of the decoder, and the encoder-decoder self-attention pays attention to the input sequence of the decoder.
The attention was replaced by Google, due to its expensive computing needs as well as the time required to train the model was huge. When they tried the same with Fast Fourier transform, the model got trained in must lesser time as compared to the self-attention, with the similar accuracy.
9 May 2021
Google replaces the Bert Self-attention with Fourier Transform
FNet: Mixing Tokens with Fourier Transforms proposed that the replacement of self-attention with simple standard unparameterized Fourier transform in the encoder can speed it up massively with good accuracy. The Fast Fourier transform is an optimized version for discrete Fourier transform. It extracts useful features from the signal fed to it. It runs 7 times faster on GPUs and twice as fast on TPUs. It’s the most effective way for mixing tokens. Also while processing data through fast Fourier transform a very little information is lost which makes it more beneficial.
FFTs were first discussed by Cooley and Tukey (1965), It is mostly used in signal processing which decomposes a signal into its constituent frequencies, its also used in image processing which decomposes the image into its sine and cosine components. FFT contributes to deep learning for ages, Some of its applications are speeding up the convolutions, Fourier RNN, etc.
The Fourier transform sublayer applies 1D Fourier transform to the sequence dimension as well as 1D to the hidden dimension.

FNET Encoder Architecture
FNet is a layer normalized ResNet architecture with multiple layers, each of which consists of a Fourier mixing sublayer followed by a feed-forward sublayer. [source]
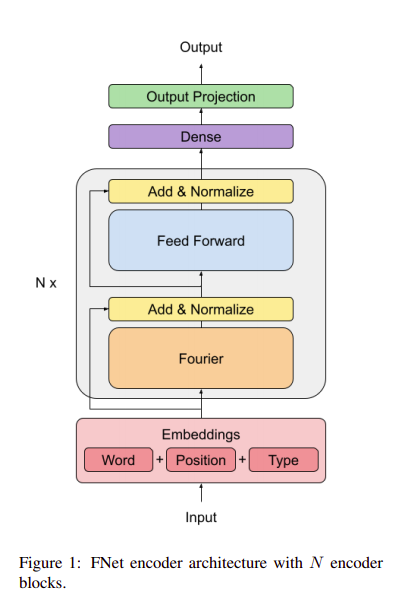
The above model architecture is the BERT model with Fourier transform
The Architecture of the encoder is kept the same with just a small change by replacing the self-attention with Fourier transform. It’s just another cool way to mix the input tokens up which provides supreme particulars to the feed-forward layer. The linear transformation in the Model accelerates the training with good performance. There is no weight concept involved as we see casually in our neural nets, where learnable weights come into play during training. This also acts as a factor that increases the acceleration and making the model lightweight.
Implementation
# FNet Encoderimport torchfrom torch import nnfrom torch.nn import functional as Fclass ff(nn.Module):
def __init__(self, dim, hidden_dim, dropout): super().__init__() self.net = nn.Sequential( nn.Linear(dim, hidden_dim), nn.GELU(), nn.Dropout(dropout), nn.Linear(hidden_dim, dim), nn.Dropout(dropout) ) def forward(self, x): return self.net(x)class FNetLayer(nn.Module): def __init__(self, dim, hidden_dim, dropout): super().__init__() self.norm = nn.LayerNorm(dim) self.feedForward = ff(dim, hidden_dim, dropout) def forward(self, x): residual = x x = torch.fft.fft2(x, dim=(-1, -2)).real # Here it is x = self.norm(x+residual) x = self.feedForward(x) x = self.norm(x+residual) return xclass FNet(nn.Module): def __init__(self, dim, hidden_dim, dropout, layers): super().__init__() self.Encoder = FNetLayer(dim, hidden_dim, dropout) self._layers_e = nn.ModuleList() for i in range(layers): layer = self.Encoder self._layers_e.append(layer) def forward(self, x): for e in self._layers_e: x = e.forward(x) return xmodel = FNet(dim=256, hidden_dim=512, dropout=.5, layers=2)print(model)x = torch.randint(1, 20, size=(20, 256))output = model(x)
For full code, visit the below link
Instinctively, Fourier transforming is just encoding the input as a linear combination of the embeddings (which we fed as positional and word embeddings to the encoder). These combined embeddings are further mixed up with the non-linearities in the feed-forward network. This is just a simple algorithm as compared to self-attention which makes wonders.
Output
here is the model summary with output.

I the following python code, we have implemented just the encoder without positional embedding and the final dense layer. The Fast Fourier Transform layer imported from the torch library transforms the vectorized input sequence to one dimensional discrete Fourier tensor. where dim is the sequence length and hidden_dim is the model hidden dimensions discrete Fourier transform is defined by the formula.

What if we used FFT in GPT? Please comment below opinion.
The Google Bert with self-attention which is only 8% more accurate than BERT with Fast Fourier transform in the GLUE benchmark but FFT 7 times faster to compute in a GPU
In simple terms, Fourier transform is an algorithm that transforms a complex temporal signal, into simpler subcomponents defined by a frequency.
References
Share :