May God bless you with all the data structure skills. Transformers have been revolutionary models that yield state-of-art variants like BERT, GPT, mt5, T5, tapas, Albert, Robert, and many more from their families. The Hugging face library has provided excellent documentation with the implementation of various real-world scenarios.
Here, we’ll try to implement the Roberta model for the question answering system. Rather than directly diving into our code, we’ll revise some theoretical concepts that are mandatory to understand the code. Believe me, it takes a slightly longer span for a newcomer into Natural language processing to understand the logic behind the code. I tried my best in explaining it conceptually. It’s also the duty of the reader to try understanding the code by going through it simultaneously until you don’t get it, and browsing stuff that you aren’t able to know within this article will definitely work for you.
Terms you should be familiar of
Tokens: Tokens are the building blocks of natural language processing. The tokens are created after the tokenization of text. Tokenization can mainly be categorized into word, character, and subword, i.e. the n-gram characters tokenization.
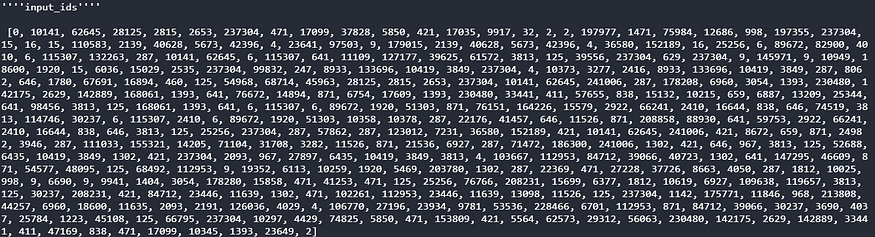
input_ids: input_ids are token indices; they are the numerical representations of tokens; a list of these representations is called sequences used as input by the model.
input_ids
sequence_ids: Sequence_ids tell us which part in the sequence is the question and which of these is the answer. The unique tokens are encoded as None, where 0’s are questions, and 1’s are context.
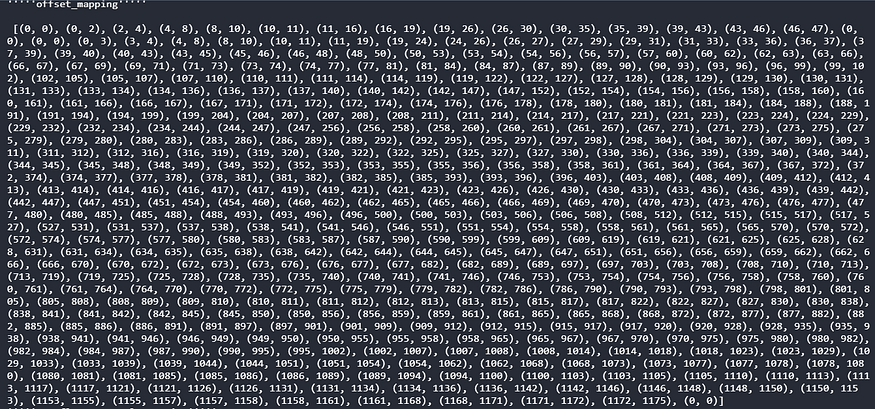
offset_mapping: offset_mapping parameter provides us with the token’s position, which is a tuple of the start and end index of the tokens that makes it easy to find their original position.
overflow_sampling: Like how the examples, i.e. the context, are truncated due to the max_length limit, so the trimmed part is continued in the following sequence with a confident stride rate, the overflowing sample is the map of how many splits is the context fitted. Like in the below image, the 0’s are the first context in the dataset, which was big enough and hence is held in lots of splits.
max_length: The constant length defined for the sequence to be processed and fed to the model.
Padding: padding satisfies the sequence with the given max_length like if the max_length is 20 and our text has only 15 words, so after tokenizing it, the text will get padded with 1’s to get the sequence length of 20. The padding can be done from the front as well as the end of the sequence.
Stride: Stride is the rate with how much token length the truncated sequence should be patched with the next one. It is basically used to handle the overflow.
Truncation: cutting the sequence after the max_length is reached.
start_token/end__token: The starting token of a specific observation needs to be fetched, for example, the start token of answers in the context, and the similar is the end token which is the ending token of that answer.
attention_mask: Attention masks tell the attention mechanism in the model to exclude the paddings that aren’t the actual tokens. It makes us easy to distinguish between the actual tokens and the padding in the combined sequence.
ROBERTA Tokenization style
Roberta uses the byte-level Byte-Pair-Encoding method derived from GPT-2. The vocabulary consists of 50000-word pieces. \U0120 as the unique character is used in the byte pair encoding, which hasn’t been made visible to us by hugging face. BPE is like a data compression algorithm in which the most common pair of consecutive bytes of data is replaced with a byte that does not occur in that Data.
Consider data ggghgghggh during encoding this Data. The byte pair gg occurs most often, so we will replace it with K. The rare words are broken down into more subword tokens. So this is a basic idea behind BPE.
Model
Roberta stands for Robustly Optimized BERT Pre-training Approach trained on 160 GB of data like the BookCorpus (Zhu et al., 2015), Wikipedia, and some additional data. Robert is just a BERT acquainted with dynamic masking, and without next sentence prediction, like how usually BERT is pretrained with masked language modelling and next sentence prediction, the NSP is eliminated in the case of Roberta model. I won’t detail the internal model working, which I have already explained in my previous posts.
Implementation
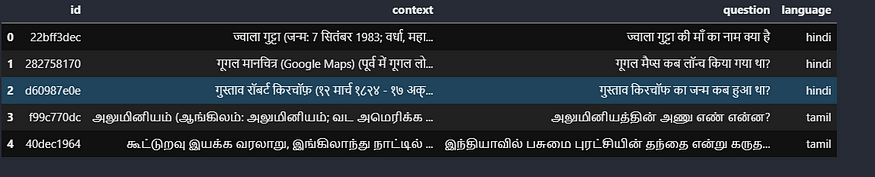
In this competition, you will be predicting the answers to questions in Hindi and Tamil. The answers are drawn directly (see the Evaluation page for details) from a limited context. We have provided a small number of samples to check your code with. There is also a hidden test set.
All files should be encoded as UTF-8.
Steps included in the project:
Loading the training and test data that was already given in my case.
Preprocessing data seems one of the challenging parts of the overall problem. This includes preparing the training and validation features.
Training the model on our preprocessed Data
postprocessing
prediction
The data was taken from the Kaggle competition “chaii — Hindi and Tamil Question Answering” hosted by Google. Here’s the link to the data. Our task is to Identify the answer to questions found in Indian language passages in the dataset. The columns in the data include id context question answer_text answer_start language.
The training set has 747 Hindi and 368 Tamil examples. In the test data, we have provided 5 examples; we don’t have answer_text and answer_start. We have been provided with the context, question, answer_text, and answer_start. We just need to find the answer in the context using start and end span. We just need to predict the answer text.
Defining a function that will prepare training data for us.
def prepare_train_features(examples):
examples["question"] = [q.lstrip() for q in examples["question"]]
tokenized_examples = tokenizer(
examples["question" if pad_on_right else "context"],
examples["context" if pad_on_right else "question"],
truncation="only_second" if pad_on_right else "only_first",
max_length=max_length,
stride=doc_stride,
return_overflowing_tokens=True,
return_offsets_mapping=True,
padding="max_length",
)
sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
offset_mapping = tokenized_examples.pop("offset_mapping")
tokenized_examples["start_positions"] = []
tokenized_examples["end_positions"] = []for i, offsets in enumerate(offset_mapping):
input_ids = tokenized_examples["input_ids"][i]
cls_index = input_ids.index(tokenizer.cls_token_id)
sequence_ids = tokenized_examples.sequence_ids(i)
sample_index = sample_mapping[i]
answers = examples["answers"][sample_index]
if len(answers["answer_start"]) == 0:
tokenized_examples["start_positions"].append(cls_index)
tokenized_examples["end_positions"].append(cls_index)
else:
start_char = answers["answer_start"][0]
end_char = start_char + len(answers["text"][0])
token_start_index = 0
while sequence_ids[token_start_index] != (1 if pad_on_right else 0):
token_start_index += 1
token_end_index = len(input_ids) - 1
while sequence_ids[token_end_index] != (1 if pad_on_right else 0):
token_end_index -= 1
if not (offsets[token_start_index][0] <= start_char and offsets[token_end_index][1] >= end_char):
tokenized_examples["start_positions"].append(cls_index)
tokenized_examples["end_positions"].append(cls_index)
else:
while token_start_index < len(offsets) and offsets[token_start_index][0] <= start_char:
token_start_index += 1
tokenized_examples["start_positions"].append(token_start_index - 1)
while offsets[token_end_index][1] >= end_char:
token_end_index -= 1
tokenized_examples["end_positions"].append(token_end_index + 1)
breakreturn tokenized_examples
Let us see how exactly this function works.
We’ll be passing the training data to this function. Firstly, the whitespace will be removed, which is present on the left of some questions in train data. Next is one of the extensive steps which is used in every transformer model, the tokenizer. The tokenizer tokenizes sentences into chunks, as shown below.
<s> sequence_1 </s></s> sequence_2 </s>
Where <s> is the classifier token and </s> is the separator token. We pass the question and context to the tokenizer, checking whether the tokenizer padding position is on the right or left, but it is to the left by default. So the tokenizer will tokenize the sequences along with padding the sequences with max_length to satisfy the given sequence limit. We have added a truncation parameter to the tokenizer that truncates the sequence after the max_length limit. The stride specifies that by what length of tokens the sequence should overlap with the previous overflowed sequence. While truncating sequences, we may lose a lot of data which isn’t a good practice in terms of data science. To overcome this problem, we need to return the overflowed sequences to forward them to further sequence to get overlapped with them. We also return the offset mappings, which gives us the map of the positions of the tokens.
In the next step, we extract the sample mapping that counts the split of a pair it has made. As we know the offset_mapping gives us the positional information of the sequences. Lastly, we start collecting the start and end tokens with some logic applied in the loop. We extract the sequence_ids, which helps us to distinguish between the question and context. The cls_index is the classifier token index. The function above processes a single sample at a time. In the case where the answer does not exist in the context, we place the start and end positions. The sample_index is the index of the example containing this span of text, i.e. the sample mapping index. Finally, we’ll collect the start and end index of the specific instance in the loop; if the answer is not in the example, we’ll label it with the CLS token; otherwise, we’ll move the start and end index to the starting ending points of the answers. The function returns the list of preprocessed examples.
Before passing the train data to the feature preparation function, we need to create a dimension named answers consisting of answer_start and answer_text; further, we generate a random sample of the data and represent the Dataset object from a pandas DataFrame.
Configure the training parameters. The data_collator automatically performs padding on the model inputs in a batch to the length of the most extended example in the dataset that eliminates the need to set a maximum sequence length that is usually fixed, resulting in an accelerated performance.
The trainer.train() starts the training and thereafter it saves the model.
def prepare_validation_features(examples):
examples["question"] = [q.lstrip() for q in examples["question"]]
tokenized_examples = tokenizer(
examples["question" if pad_on_right else "context"],
examples["context" if pad_on_right else "question"],
truncation="only_second" if pad_on_right else "only_first",
max_length=max_length,
stride=doc_stride,
return_overflowing_tokens=True,
return_offsets_mapping=True,
padding="max_length",
)
sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
tokenized_examples["example_id"] = []for i in range(len(tokenized_examples["input_ids"])):
sequence_ids = tokenized_examples.sequence_ids(i)
context_index = 1 if pad_on_right else 0
sample_index = sample_mapping[i]
tokenized_examples["example_id"].append(examples["id"][sample_index])
tokenized_examples["offset_mapping"][i] = [
(o if sequence_ids[k] == context_index else None)
for k, o in enumerate(tokenized_examples["offset_mapping"][i])
]return tokenized_examples
For validation, we don’t need to compute start and end positions; instead, we’ll collect the examples that combine to make a feature. The sample_mapping key gives us the map that provides information on the correspondence between the context and the split features from it due to the max_length limit. We’ll take the sequence_ids to know where exactly the question and context lie in the sequences. The pad_to_right is True, so the context index will be 1. Lastly, we’ll be setting the offset_mapping to None that aren’t included in the context, making it simpler to detect the context.
In the same way as like train set we’ll be applying the prepare_validation_features function to the data.
The below block of code informs us about the number of features an example is split in and gives us the list of examples and their features.
max_answer_length = 30examples = valid_dataset
features = validation_features
example_id_to_index = {k: i for i, k in enumerate(examples["id"])}
features_per_example = collections.defaultdict(list)
for i, feature in enumerate(features):
features_per_example[example_id_to_index[feature["example_id"]]].append(i)
Postprocessing: Postprocessing converts the predictions of a question-answering model to answers that are substrings of the original contexts. The Postprocessing code consists of nested loops over the examples. It collects the indices of the features of ongoing examples in the loop and also the context. Furthermore, it loops over each of the features in the continuing example and collects predictions on the same features from the model consisting of two arrays containing the start logits and the end logits, respectively. The min_null_score is None which has to use during training on squad v2 data. The null answer is scored as the sum of the start_logit and end_logit associated with the [CLS] token that is our minimum null score. Any sensible combination of start and end logits, i.e. start_logit + end_logit can be considered a possible answer. Higher the combination score higher is the confidence of getting the best answer. If the End token falls before the start token, in this case, it should be excluded. Answers in which the start or end tokens are associated with question tokens are also excluded, as we know the answer to the question will not be obvious in the question. The number of best predictions for each example can be adjusted with the — n_best_size argument; the code goes through all possibilities to get the best answer. Answers with a length that is either less than 0 or greater than the max_answer_length are not included; neither answer out of scope is considered.
from tqdm.auto import tqdm
def postprocess_qa_predictions(examples, features, raw_predictions, n_best_size = 20, max_answer_length = 30):
all_start_logits, all_end_logits = raw_predictions
example_id_to_index = {k: i for i, k in enumerate(examples["id"])}
features_per_example = collections.defaultdict(list)
for i, feature in enumerate(features):
features_per_example[example_id_to_index[feature["example_id"]]].append(i)
predictions = collections.OrderedDict()
for example_index, example in enumerate(tqdm(examples)):
feature_indices = features_per_example[example_index]
min_null_score = None
valid_answers = []
context = example["context"]
for feature_index in feature_indices:
start_logits = all_start_logits[feature_index]
end_logits = all_end_logits[feature_index]
offset_mapping = features[feature_index]["offset_mapping"]
cls_index = features[feature_index]["input_ids"].index(tokenizer.cls_token_id)
feature_null_score = start_logits[cls_index] + end_logits[cls_index]
if min_null_score is None or min_null_score < feature_null_score:
min_null_score = feature_null_score
start_indexes = np.argsort(start_logits)[-1 : -n_best_size - 1 : -1].tolist()
end_indexes = np.argsort(end_logits)[-1 : -n_best_size - 1 : -1].tolist()
for start_index in start_indexes:
for end_index in end_indexes:
if (
start_index >= len(offset_mapping)
or end_index >= len(offset_mapping)
or offset_mapping[start_index] is None
or offset_mapping[end_index] is None
):
continue
if end_index < start_index or end_index - start_index + 1 > max_answer_length:
continue
start_char = offset_mapping[start_index][0]
end_char = offset_mapping[end_index][1]
valid_answers.append(
{
"score": start_logits[start_index] + end_logits[end_index],
"text": context[start_char: end_char]
}
)
if len(valid_answers) > 0:
best_answer = sorted(valid_answers, key=lambda x: x["score"], reverse=True)[0]
else:
best_answer = {"text": "", "score": 0.0}
predictions[example["id"]] = best_answer["text"]
return predictions
We will be passing the valid_dataset, validation_features, raw_predictions to the postprocess_qa_predictions function to get the final predictions.
So this is it, if you still haven’t understood this, I recommend you to go at least 3 times through this whole post. And also try browsing through the web for the topic you are not understanding, I am sure you will.

 input_ids
input_ids