*Sed ut perspiciatis unde omnis iste natus error sit voluptatem accusantium
Linear regression (No loitering)
Let’s understand the linear regression without any elaboration and in a short manner, that won’t waste your time rather than it will deliver you just the needed information. That will help you to grasp the linear regression and would also make your way easy to know logistic regression.
What you will learn
An overview of the basics.
Working
Cost function
Gradient Descent
Assumptions
Implementing in python from scratch
Metrics in linear regression
A Quick Helper
Let’s start with becoming familiar with some terminologies and concepts needed to understand the actual algorithm.
If we split the word linear regression. Here “linear” word, just consider it as a line and regression can be defined as the linear relation between the dependent and independent variable. It can be represented by Y=mx+c
Where Y is the dependent variable, which has to be predicted(also known as a response, observation). m is the slope i.e the steepness in the line also known as gradient or a coefficient. x is the independent variable (also known as a predictor, exploratory variable) that is the data, And c is the intercept i.e the starting end that crosses the y-axis.
The linear regression can be further classified as simple linear regression and multiple linear regression. Simple linear regression involves a single variable, whereas multiple linear regression involves multiple variables.
The relation between the independent and dependent variables is observed using correlation.
Residual is the error term that is obtained by subtracting the predicted values from the actual values.
The predictions of linear regression are always continuous.
If the Y-axis value is constant, then the slope formed will be negative ( y = -mx + c ).
How it Works.
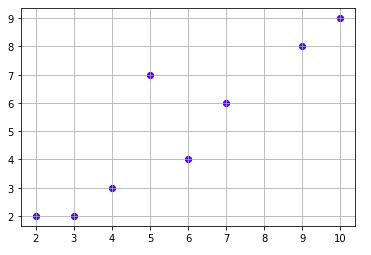
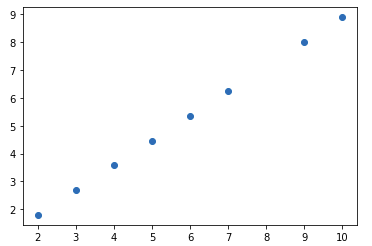
Taking into consideration the above graph that is plotted using the coordinates x = {3, 6, 4, 5, 2, 7, 9, 10}, y = {2, 4, 3, 7, 2, 6, 8, 9}
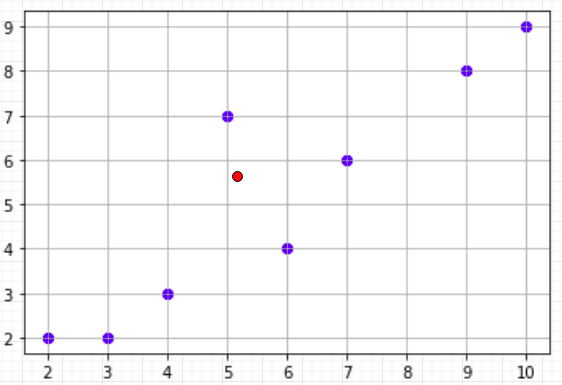
By calculating the mean of x and y we get mean as x_mean = 5.75 & y_mean = 5.12, after plotting these mean values we get the below diagram.
The red dot is plotted as per the mean of x and y coordinates.
Let’s now see, how exactly the slope is calculated.
slope
where x is the values on the x-axis, x` is the mean of x values on the x-axis i.e x_mean. y` is the mean of y values on the y-axis i.e y_mean.
y = mx + c, where y is the y_mean, m is the recently calculated slope, x is the x_mean and c is the intercept. After placing values in the equation of y = mx+ c, we get c = 0.022522522522521626.
Now we have our values ready, where
c = 0.022522522522521626
m = 0.88726566761
y_pred =m(x)+c
you might be aware of the next step, we’ll be inserting each x value in the equation and predicting y. So let’s do it.
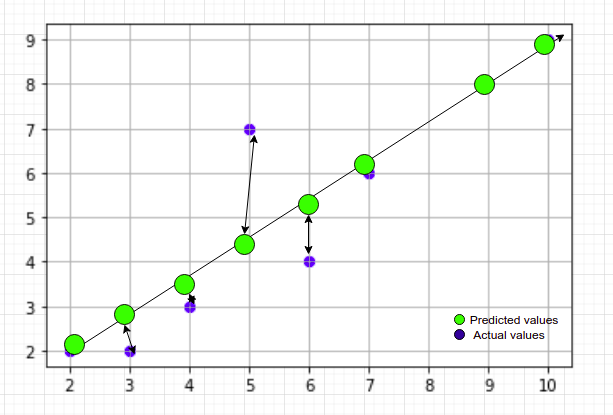
If we try to visualize the actual and the predicted values, we get
predictions v/s actuals
As we know the distance between the actual and the predicted values is known as residual(error) and we need to minimize this error till we get the best fit line.
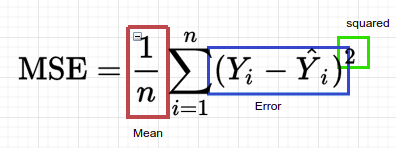
Cost Function
Mean squared error
Mean square error is the cost function used to calculate the error, the less the error the better the regression model. cost and loss functions refer to the same thing. The cost function is calculated as an average of the loss function at the end. Whereas the loss function is a value that is calculated at every iteration.
let’s try calculating the MSE for our predicted line, after summing the squared error and taking the mean of it I got 1.1463963963963963.
Mainly, linear regression can be categorized into Simple Linear Regression using Least Squares and Simple Linear Regression using Gradient Descent. You might be wondering what’s the difference is and why don’t we use the analytical approach i.e the OLS?
The ordinary least square method is a non-iterative method whereas the gradient descent is iterative.
Gradient Descent
Gradient Descent
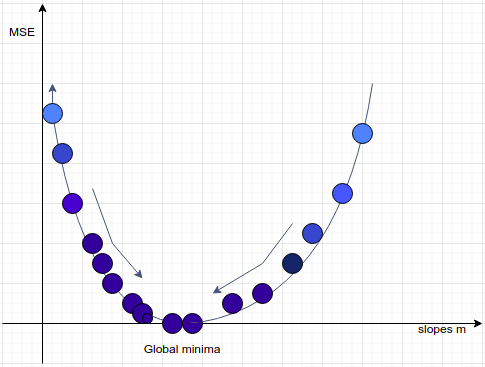
Gradient descent is an optimization technique used in many machine learning algorithms. It finds out the best parameters for the model in order to minimize the cost function which leads to the regression line with the best fitting.
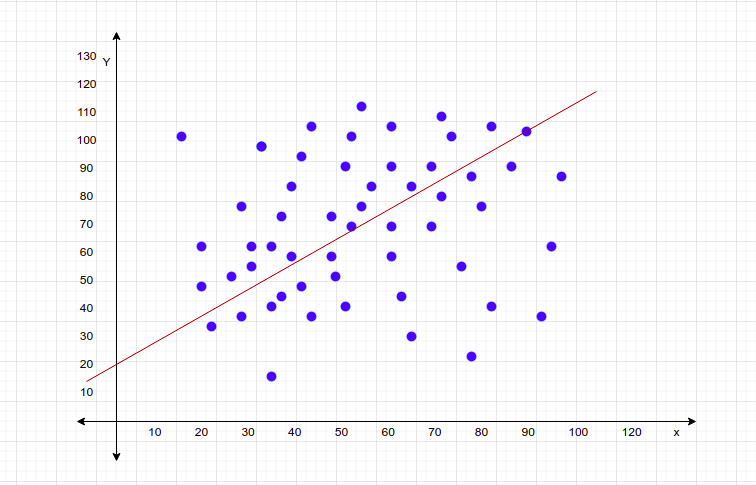
In the diagram above we have plotted the slope obtained at every iteration w.r.t the values of the cost function that gives us this kind of curve. The lowest point on the curve is called the global minima which is the slope with the lowest error value. That indicates the best fitting.
The gradient descent involves an additional parameter, the learning rate, that decides the moment of the gradient, whether to take larger steps or to move gradually toward the minima point. The motive of the gradient descent is to move toward the global minima, but the speed of the moving gradient depends upon us, which can be adjusted using the learning rate. Usually, the learning rate parameter is kept minimum, something like 0.001. If we set it as a bigger number then it will be unstable, it will take bigger steps and never reach the destination i.e the global minima. Reaching the minimal point means that we are getting the best results with minimum error and hence the regression line formed is the best-fitted line. As we know that gradient descent is an iterative algorithm, but what it means exactly?
At every iteration, the gradient descent updates the weights of the model. The weights are nothing but the slope(m) and the intercept(c). Step involved in gradient descent algorithm are:
Initialize the values of m and c randomly (usually it is 0).
Define the learning rate.
Calculate Dm that represents the partial derivative of the cost function with respect to the slope. That implies the difference in the cost function if the change is made to the slope m. The partial derivatives are calculated using the chain rule.
Calculate Dc that represents the partial derivative of the cost function with respect to c. That implies the difference in the cost function if the change is made to intercept c.
Updating the values of m and c.
And the whole flow iterates till we get the least cost value.
Before we apply the linear model to any of the problems, that data must pass the eligibility criteria below. If it doesn’t match the requirements, then the linear regression won’t work or will not deliver proper predictions.
Assumptions
Linearity: The relationship between X and the mean of Y is linear. This means there must be a linear relationship between X and Y. A single outlier can be critical for a linear regression model. A scatter plot may help you to analyze the outliers.
Homoscedasticity: The variance of residual is the same for any value of X. That means the variance of the residual that is, the “noise” is the same across the regression line.
Independence: There must be no multicollinearity which denotes that the independent variables should not be correlated with each other.
Normality: The errors should be normally distributed.
Implementing linear regression using python
# import packages
import numpy as np
from numpy.random import randn, randint
from numpy.random import seed
from matplotlib import pyplot as plt
#initialize label and target
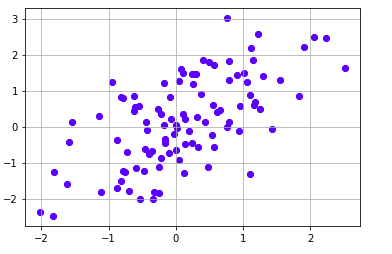
x=np.random.randn(100)
y=np.random.randn(100)+x
#visualize the data
plt.scatter(x,y, c = 'blue',cmap='viridis')
plt.grid()
plt.show()
We can see linearity in the data, this is due to the y variable being the combination of x and y itself.
Data visualization
formula for partial derivative of slope and intercept formula for updating the intercept and slope
c, m = 0.0,1.0
lr = 0.000001
epochs = 40
error = []
epoch_cost = []
predictions = []
for epoch in range(epochs):
cost_c, cost_m = 0, 0
for i in range(len(x)):
#Making predictions
y_pred = (c + m*x[i])
predictions.append(y_pred)
print('epoch:',epoch ,'cost:',((y[i] - y_pred)**2)/len(y))
#Updating coeff.
c = c - lr * cost_c
m = m - lr * cost_m
error.append(epoch_cost)
#plotting the prediction
pred = predictions[-100:]
plt.scatter(x,pred, c = 'red',cmap='viridis')
plt.scatter(x,y, c = 'blue',cmap='viridis')
plt.grid()
plt.show()
We can see the regression line formed is passing through the center of the data, which shows it has predicted a line considering every data point. There may also be some outliers which we didn’t analyze, as we just focused on the working part, but outlier impacts the data that leads to improper predictions.
Multiple Linear regression
Similar to the simple linear regression, we can implement the multiple linear regression with just a simple change i.e we just have to sum up operations on all the variables and keep everything as it is. It uses several explanatory variables to predict the outcome of a response variable.
The assumptions in multiple linear regression are that there should be a linear relationship between both the dependent and independent variables. Also, there should be no dense correlation between the independent variables.
Enough for today guys, Hope you all understood behind the scene of the linear regression model. Feel free if any query occurs. Lets get connected on Linkedin

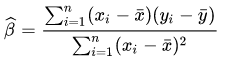
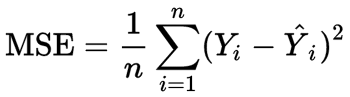
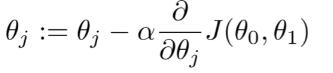
 Data visualization
Data visualization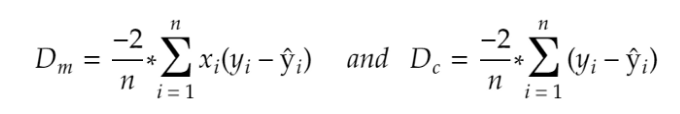 formula for partial derivative of slope and intercept
formula for partial derivative of slope and intercept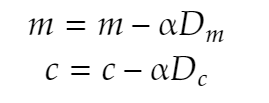 formula for updating the intercept and slope
formula for updating the intercept and slope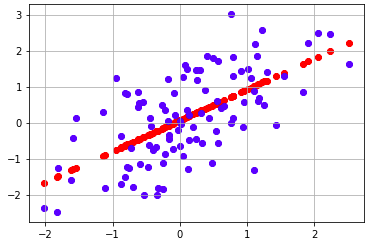
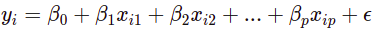
Thank you for the information.
thanks for showing support rohit