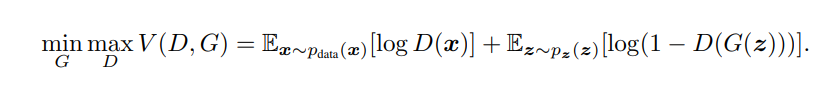*Sed ut perspiciatis unde omnis iste natus error sit voluptatem accusantium
Writing after a long time, Here’s the basic + in-depth mix explanation of Generative adversarial networks and Style-Based Generative Adversarial networks.
Introduction
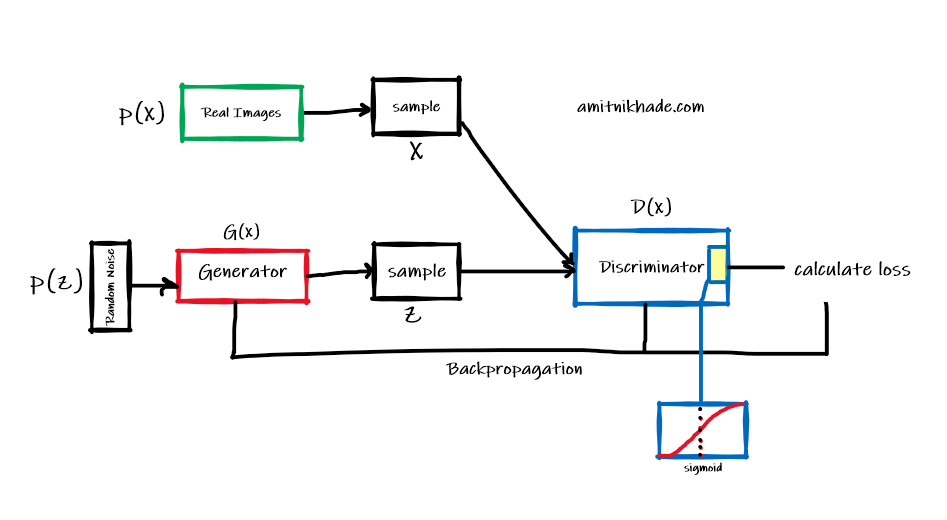
GAN is simply a generative model that generates new data from the input data. They are used to perform unsupervised operations. They work majorly with image data and also audio data. The Generative adversarial networks consist of a generator and a discriminator. Both are kinds of neural networks that compete with each other. GANs are very computationally expensive with a requirement of extremely high-end GPUs and lots of time to get trained.
Generator
The generator is a neural network that creates fake data and tries to confuse the discriminator in such a way that it takes a random noise as an input and the input sample is reconstructed to some new data(for example, a random data vector of a vectorized image is converted into a new unknown image i.e a new image is generated using the random sample). In conclusion, the Generator outputs the newly generated image.
Discriminator
The discriminator is a neural network that tries to distinguish between fake and real data. We know that there are two input sources to our discriminator, one is the real image sample and the other is our generated image. When we pass real data through the discriminator, its task is to classify whether it is fake or real, and the same task is performed when the fake data is passed through the discriminator. And probably the discriminator may output the expected output.
Let us see the in-depth working of both the neural network and how they get clashed with each other.
Working
Let us understand the working for the whole architecture in layman’s language. As we know the basic working of the Generator as well as the discriminator we can now proceed further like how exactly they come into play.
GAN’s Architecture
Firstly, the discriminator is trained on the real data, the random noise is fed to the generator, from which it generates new data. Then the generated data is fed to the discriminator and the output of the discriminator is the classification result, whether the input is fake or original. And based upon the following results the loss is calculated and feedback is provided to the generator as well as the discriminator through backpropagation similar to the neural network to obtain gradients and it uses gradients to update the weight. Whereas the discriminator is trained to classify the real image, so whenever the generated image is passed to the discriminator after every iteration, the discriminator keeps on classifying the images and the generator keeps generating new fake images until it doesn’t fool the discriminator. And a time comes when the generator succeeds in fooling the discriminator, and that’s what we want.
In mathematical terms, the generator grasps the data distribution, and the discriminator estimates the probability of the input, that it came from the real data rather than the output of the generator. (probability of the input data i.e the generator’s output, belonging to the real data)
The aim of the discriminator is to predict the correct class but the generator tries to fool the discriminator by generating fake data.
The Generator learns how to generate data in such a way that the Discriminator will not be able to distinguish it as fake anymore. The clash between the generator and discriminator improves their knowledge until the Generator creates data almost similar to the real data. Both the networks compete against each other and hence they are is known as adversarial
Mainly the strategy adopted by the competition between G and D is that we train D to maximize the probability of assigning the correct label to both real samples and generated data. And G is trained to minimize the probability of correct classification by confusing it with fake data.
The GANs are formulated as a minimax game, where the Discriminator is trying to minimize its reward V(D, G) and the Generator is trying to minimize the Discriminator’s reward or in other words, maximize its loss. It can be mathematically described by the formula below:
Where,
G = Generator
D = Discriminator
P(x) = distribution of real data
P(z) = distribution of generator
x = P(x) sample
z = P(z) sample
D(x) = Discriminator
G(z) = Generator
You will be shocked if I say that person of this face does not exist on this earth. But that’s true. The image is generated by a modified gan variant (Style GAN) in association with Keras and Nvidia. You can try this awesome web application over here.
Image dataset (In my case I used the celebrity face dataset from Kaggle, you can download it from here)
Code:
import tensorflow as tf
import keras
from keras import layers
import numpy as np
import matplotlib.pyplot as plt
import cv2
import os
from tqdm import tqdm
import re
from keras.preprocessing.image import img_to_array
import time
the generator network takes a random vector from the normal distribution as input. which is further passed through the dense layer and by reshaping it is finally fed through Convolution layers. Convolution layers play the role of downsampling of our latent vector, after a series of convolution batch normalization and LeakyRelu layers our downsampled latent vector is upsampled using Conv2DTranspose. The final output layer of the Generator generates 128 by 128 by 3 images. In short, the generator is like an autoencoder that downsamples input data and upsamples it.
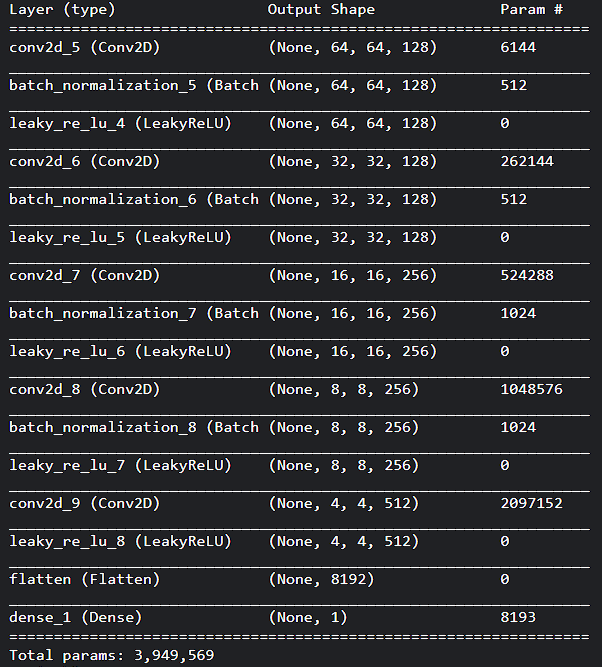
the discriminator model takes 128, 128, 3 images that can be real or generated. This input image is downsampled using the Convolution layer and by flattening it is fed to the final neuron to distinguish between real and fake images. Since we use the sigmoid function as activation, it output value in between 0 and 1. Here value greater than 0.5 refers to real and less than 0.5 refers to a fake image. The output of the discriminator is used in the training of the generator in a form of feedback.
def train_steps(images):
noise = np.random.normal(0,1,(batch_size,latent_dim))
with tf.GradientTape() as gen_tape , tf.GradientTape() as disc_tape:
generated_images = generator(noise)
fake_output = discriminator(generated_images)
real_output = discriminator(images)
gen_loss = generator_loss(fake_output)
dis_loss = discriminator_loss(fake_output, real_output)
gradient_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradient_of_discriminator = disc_tape.gradient(dis_loss, discriminator.trainable_variables)
optimizer.apply_gradients(zip(gradient_of_generator,generator.trainable_variables))
optimizer.apply_gradients(zip(gradient_of_discriminator, discriminator.trainable_variables))
loss = {'gen loss':gen_loss,
'disc loss': dis_loss}
return loss
Train
def train(epochs,dataset):
for epoch in range(epochs):
start = time.time()
print("\nEpoch : {}".format(epoch + 1))
for images in dataset:
loss = train_steps(images)
print(" Time:{}".format(np.round(time.time() - start),2))
print("Generator Loss: {} Discriminator Loss: {}".format(loss['gen loss'],loss['disc loss']))
Start the training
train(epochs,dataset)
Epoch : 1
Time:31.0
Generator Loss: 1.2972465753555298 Discriminator Loss: 0.3216813802719116
Epoch : 2
Time:28.0
Generator Loss: 13.50732707977295 Discriminator Loss: 2.409525950497482e-05
Epoch : 3
Time:28.0
Generator Loss: 9.731826782226562 Discriminator Loss: 7.139644731068984e-05
Epoch : 4
Time:28.0
Generator Loss: 10.45062255859375 Discriminator Loss: 5.9580266679404303e-05
Epoch : 5
Time:28.0
Generator Loss: 16.217674255371094 Discriminator Loss: 5.710946425097063e-05
Epoch : 6
Time:28.0
Generator Loss: 9.023109436035156 Discriminator Loss: 0.00012306204007472843
Epoch : 7
Time:28.0
Generator Loss: 12.984770774841309 Discriminator Loss: 3.3322144190606195e-06
Epoch : 8
Time:28.0
Generator Loss: 13.828323364257812 Discriminator Loss: 1.3120832136337413e-06
Epoch : 9
Time:28.0
Generator Loss: 9.400060653686523 Discriminator Loss: 8.484505815431476e-05
Epoch : 10
Time:28.0
Generator Loss: 35.195343017578125 Discriminator Loss: 5.935515190458318e-09
Epoch : 11
Time:28.0
Generator Loss: 34.00908279418945 Discriminator Loss: 1.0052567667173662e-09
Epoch : 12
Time:28.0
Generator Loss: 8.498176574707031 Discriminator Loss: 0.00023046032583806664
Epoch : 13
Time:28.0
Generator Loss: 43.04578399658203 Discriminator Loss: 1.3833667544815853e-08
Epoch : 14
Time:28.0
Generator Loss: 52.867767333984375 Discriminator Loss: 0.018963398411870003
Epoch : 15
Time:28.0
Generator Loss: 22.505146026611328 Discriminator Loss: 3.532684900164895e-07
Note: This code is just for implementation and not for any productive use. As we can see the unstable behaviour during training the generater loss bounces a lot, this is just an instance of the usage of GAN's
plot results
def plot_generated_images(square = 5, epochs = 0):
plt.figure(figsize = (10,10))
for i in range(square * square):
if epochs != 0:
if(i == square //2):
plt.title("Generated Image at Epoch:{}\n".format(epochs), fontsize = 32, color = 'black')
plt.subplot(square, square, i+1)
noise = np.random.normal(0,1,(1,latent_dim))
img = generator(noise)
plt.imshow(np.clip((img[0,...]+1)/2, 0, 1))
plt.xticks([])
plt.yticks([])
plt.grid()
plot_generated_images(7)
Types of GANs:
There have been many different types of GAN implementation. Some of the commonly used models are as follows:
Vanilla GAN: This is the basic type of GAN that we saw in this blog.
Conditional GAN: In CGAN, an additional parameter ‘y’ is added to the Generator for generating the matching data. Labels are used as an input to the Discriminator in order for the Discriminator to help distinguish the real data from the fake generated data.
Deep Convolutional GAN (DCGAN): In this variant, the multi-layer perceptrons are replaced by the ConvNets using strides rather than using max-pooling. Even, the layers are not fully connected.
Super Resolution GAN (SRGAN): A deep neural network is used along with an adversarial network in order to produce higher resolution images by enhancing its details minimizing errors.
Conclusion
GANs are considered to be the most prominent researchers in the history of machine learning. GANs were the primary generative algorithms to administer convincingly sensible results.