
*Sed ut perspiciatis unde omnis iste natus error sit voluptatem accusantium
This example demonstrates how a Synaptic Plasticity Network can adapt to changing patterns in a time series, making it suitable for real-world scenarios where underlying data distributions may shift over time.
Advanced Concepts and Future Directions
As research in biologically-inspired neural networks continues to advance, several exciting directions for Synaptic Plasticity Networks emerge:
1. Meta-Plasticity:
Implementing higher-order plasticity rules that allow the network to learn how to adapt its plasticity based on task requirements.
2. Neuromodulation:
Incorporating neuromodulatory signals that can globally affect the plasticity and behavior of the network, mimicking the role of neurotransmitters in biological brains.
3. Structural Plasticity:
Allowing the network to dynamically create or prune connections, changing its topology in response to input patterns.
4. Integration with Other Architectures:
Combining Synaptic Plasticity Networks with other powerful architectures like Transformers or Graph Neural Networks to create hybrid models with enhanced capabilities.
5. Continual Learning:
Leveraging the adaptive nature of SPNs to develop models that can learn continuously without catastrophic forgetting.
6. Interpretability:
Developing techniques to visualize and interpret the learned representations and adaptive behaviors of Synaptic Plasticity Networks.
Conclusion
Synaptic Plasticity Networks represent a fascinating bridge between biological neural systems and artificial neural networks. By incorporating mechanisms inspired by neural plasticity, these networks offer enhanced adaptability, context-sensitivity, and dynamic focus.
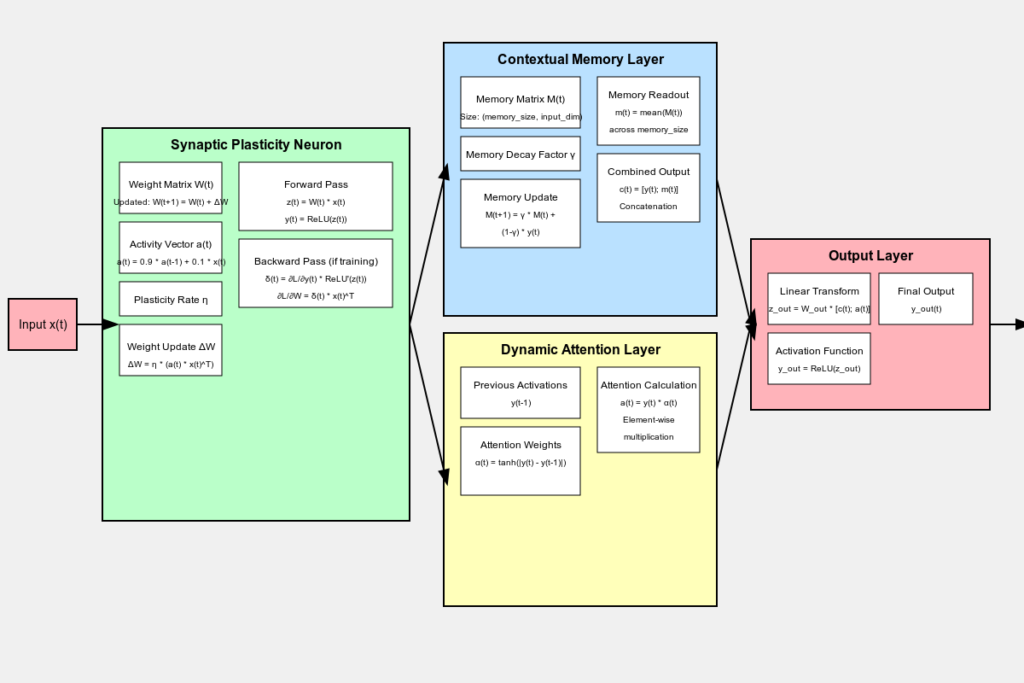
As we’ve explored in this blog post, SPNs consist of three main components: Synaptic Plasticity Neurons, Contextual Memory Layers, and Dynamic Attention Layers. These components work in concert to create a powerful, adaptive architecture suitable for a wide range of applications, particularly those involving temporal dependencies or changing data distributions.
While SPNs are still an active area of research, they show great promise in advancing the field of neural networks towards more flexible, adaptive, and biologically-plausible models. As we continue to draw inspiration from the incredible adaptability of biological brains, we can expect to see even more innovative architectures that push the boundaries of what’s possible in machine learning and artificial intelligence.
Here’s the colab notebook for complete code